Na Alura, alunos fazem diversos cursos de diversas categorias. Queremos visualizar isso. Pense por exemplo um aluno que faz 5 cursos de programação e 2 de design pode ser representado como (5,2) enquanto uma aluna que fez 10 de design e 1 de programação como (1,10). Portanto se tenho duas dimensões (programação e design) os estudantes caem num plano em R^2 (estritamente positivo) que pode ser facilmente plotado.
Pensando em estudantes que fazem muitos ou poucos cursos, podemos gerar uma quantidade (1000) aleatórias de cursos que eles fazem em Python:
import numpy as np
import pandas as pd
ALUNOS = 1000
def poucos_cursos():
return (np.random.randn(ALUNOS) + 3).astype(int)
def muitos_cursos():
return (3 * np.random.randn(ALUNOS) + 20).astype(int)
E imprimir dois exemplo de muitos cursos feitos e poucos cursos feitos:

print("Exemplo de muitos cursos ", muitos_cursos()[:5])
print("Exemplo de poucos cursos ", poucos_cursos()[:5])
Com a saída:
Exemplo de muitos cursos [21 19 21 20 15]
Exemplo de poucos cursos [4 3 1 3 4]
Ótimo, somos capazes de criar agora um conjunto de dados de alunos que fazem muitos cursos de programação e poucos de design, por exemplo:
def gera_alunos(programacao, design):
linhas = np.array([programacao, design]).T
alunos = pd.DataFrame(linhas, columns=["programacao", "design"])
return alunos
gera_alunos(muitos_cursos(), poucos_cursos())
Tendo como exemplo de resultado:
programacao design
0 18 2
1 17 2
2 16 4
3 21 3
4 19 3
Ótimo, somos capazes então de criarmos um conjunto de dados aleatório de alunos e alunas que fizeram mais programação e mais design:
programacao = gera_alunos(muitos_cursos(), poucos_cursos())
design = gera_alunos(poucos_cursos(), muitos_cursos())
alunos = programacao.append(design, sort=False)
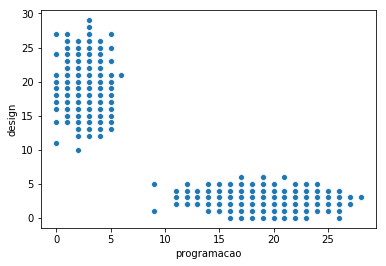
Agora podemos usar a biblioteca seaborn para plotar os alunos:
import seaborn as sns
sns.scatterplot(x="programacao", y="design", data=alunos)
Vamos colocar mais uma dimensão, cursos de mobile:
def gera_alunos(programacao, design, mobile):
linhas = np.array([programacao, design, mobile]).T
alunos = pd.DataFrame(linhas, columns=["programacao", "design", "mobile"])
return alunos
programacao = gera_alunos(muitos_cursos(), poucos_cursos(), poucos_cursos())
design = gera_alunos(poucos_cursos(), muitos_cursos(), poucos_cursos())
mobile = gera_alunos(poucos_cursos(), poucos_cursos(), muitos_cursos())
alunos = programacao.append(design, sort=False).append(mobile, sort=False).fillna(0)
sns.scatterplot(x="programacao", y="design", data=alunos)
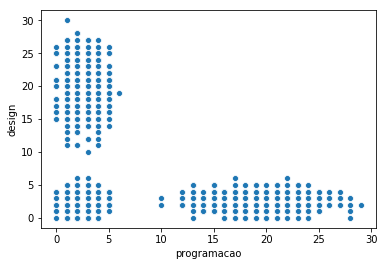
Curioso que mesmo com os dados em 3 dimensões (R^3), o gráfico permite visualizarmos os 3 grupos de alunos de maneira clara. Isso pois o grupo de mobile foi gerado intencionalmente com um número baixo de cursos de programação e design.
É comum em situações como essa desejarmos colorir cada ponto de acordo com uma característica ou categoria. Vamos definir uma categoria (texto) para cada ponto:
def gera_alunos(categoria, programacao, design, mobile):
linhas = np.array([programacao, design, mobile]).T
alunos = pd.DataFrame(linhas, columns=["programacao", "design", "mobile"])
alunos['categoria'] = categoria
return alunos
gera_alunos('programacao', muitos_cursos(), poucos_cursos(), poucos_cursos())[:5]
Que resulta em uma coluna nova chamada categoria, indicando o que escolhemos para esse grupo:
programacao design mobile categoria
0 18 3 2 programacao
1 18 2 2 programacao
2 15 2 2 programacao
3 22 1 3 programacao
4 19 3 2 programacao
Ótimo, mas o código está bastante repetitivo, que tal deixarmos valores padrão de poucos cursos para todos os cursos que não passarmos?
def gera_alunos(categoria, programacao=poucos_cursos(), design=poucos_cursos(), mobile=poucos_cursos()):
linhas = np.array([programacao, design, mobile]).T
alunos = pd.DataFrame(linhas, columns=["programacao", "design", "mobile"])
alunos['categoria'] = categoria
return alunos
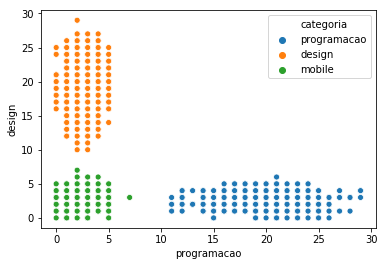
Pronto, vamos indicar no plot que queremos o tom de cor (hue) de acordo com a coluna categoria:
programacao = gera_alunos('programacao',programacao=muitos_cursos())
design = gera_alunos('design',design=muitos_cursos())
mobile = gera_alunos('mobile',mobile=muitos_cursos())
alunos = programacao.append(design, sort=False).append(mobile, sort=False)
sns.scatterplot(x="programacao", y="design", hue="categoria", data=alunos)
sns.scatterplot(x="programacao", y="design", hue="categoria", data=alunos)
E para plotar esse gráfico em 3d? Podemos usar a própria biblioteca do matplotlib para isso:
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(alunos.programacao, alunos.design, alunos.mobile, c=alunos.categoria)
Mas isso não funciona. O seaborn já é inteligente e percebe que passamos uma variável categórica (no nosso caso, uma coluna com strings distintas agrupáveis) para determinar a cor. O scatter do matplotlib é mais baixo nível e requer, nessa situação, strings que condizam com cores reais, e não categorias. Uma maneira de fazer isso é mapearmos cada categoria para uma cor com um dicionário:
cores = {'programacao':'red', 'mobile':'blue', 'design':'green'}
E agora usarmos uma lambda para mapearmos a coluna categoria pra a cor:
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(alunos.programacao, alunos.design, alunos.mobile, c=alunos.categoria.apply(lambda x: cores[x]))
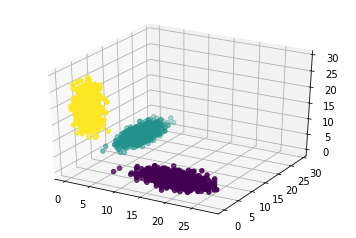
Você pode encontrar todo o código desse primeiro post no github. Dentre alguns dos cursos existentes de Data Science e Machine Learning na Alura, o plot de dados em diversas dimensões é fundamental para explorar os mesmos.